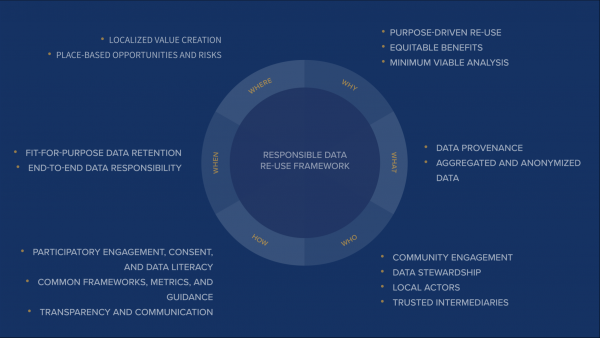
” The Governance Lab (The GovLab) at the NYU Tandon School of Engineering, with support from the Henry Luce Foundation, today released guidance to inform decision-making in the responsible re-use of data — re-purposing data for a use other than that for which it was originally intended — to address COVID-19. The findings, recommendations, and a new Responsible Data Re-Use framework stem from The Data Assembly initiative in New York City. An effort to solicit diverse, actionable public input on data re-use for crisis response in the United States, the Data Assembly brought together New York City-based stakeholders from government, the private sector, civic rights and advocacy organizations, and the general public to deliberate on innovative, though potentially risky, uses of data to inform crisis response in New York City. The findings and guidance from the initiative will inform policymaking and practice regarding data re-use in New York City, as well as free data literacy training offerings.
The Data Assembly’s Responsible Data Re-Use Framework provides clarity on a major element of the ongoing crisis. Though leaders throughout the world have relied on data to reduce uncertainty and make better decisions, expectations around the use and sharing of siloed data assets has remained unclear. This summer, along with the New York Public Library and Brooklyn Public Library, The GovLab co-hosted four months of remote deliberations with New York-based civil rights organizations, key data holders, and policymakers. Today’s release is a product of these discussions, to show how New Yorkers and their leaders think about the opportunities and risks involved in the data-driven response to COVID-19….(More)”
Richard Hughes Gibson at the Hedgehog Review: “In the last decade of the twentieth century, as we’ve seen, Howard Rheingold and William J. Mitchell imagined the Web as an “electronic agora” where netizens would roam freely, mixing business, pleasure, and politics. Al Gore envisioned it as an “information superhighway” system for which any computer could offer an onramp. Our current condition, by contrast, has been likened to shuffling between “walled gardens,” each platform—be it Facebook, Apple, Amazon, or Google—being its own tightly controlled ecosystem. Yet even this metaphor is perhaps too benign. As the cultural critic Alan Jacobs has observed, “they are not gardens; they are walled industrial sites, within which users, for no financial compensation, produce data which the owners of the factories sift and then sell.”
Harvard Business School professor Shoshanna Zuboff has dubbed the business model underlying these factories “surveillance capitalism.” Surveillance capitalism works by collecting information about you (your Internet activity, call history, app usage, your voice, your location, even your fitness level), which creates profiles of what you like, where you go, who you know, and who you are. That shadowy portrait makes a powerful tool for predicting what kinds of products and services you might like to purchase, and other companies are happy to pay for such finely-tuned targeted advertising. (Facebook alone generated $69 billion in ad revenue last year.)
The information-gathering can’t ever stop, however; the business model depends on a steady supply of new user data to inform the next round of predictions. This “extraction imperative,” as Zuboff calls it, is inherently monopolistic, rival companies being both a threat that must be eliminated and a potential gold mine from which more user data can be extracted (see Facebook’s acquisitions of competitors Whatsapp and Instagram). Equally worryingly, the big tech companies have begun moving into other sectors of the economy, as seen, for example, in Google’s quiet entry last year into the medical records business (unbeknownst to the patients and physicians whose data was mined).
There is growing consensus among legal scholars and social scientists that these practices are hazardous to democracy. Commentators worry over the consequences of putting so much wealth in so few hands so quickly (Zuboff calls it a “new Gilded Age”). They note the number of tech executives who’ve gone on to high-ranking government posts and vice versa. They point to the fact that—contrary to Mark Zuckerberg’s 2010 declaration that privacy is no longer a “social norm”—users are indeed worried about privacy. Scholars note, furthermore, that these platforms are not a genuine reflection of public opinion, though they are often treated as such. Social media can operate as echo chambers, only showing you what people like you read, think, do. Paradoxically, they can also become pressure cookers. As is now widely documented, many algorithms reward—and thereby amplify—the most divisive and thus most attention-grabbing content. Keeping us dialed in—whether for the next round of affirmation or outrage—is essential to their success….(More)”.
Don’t Fear the Robots, and Other Lessons From a Study of the Digital Economy
Nov 19, 2020 06:02 am
Steve Lohr at the New York Times: “L. Rafael Reif, the president of Massachusetts Institute of Technology, delivered an intellectual call to arms to the university’s faculty in November 2017: Help generate insights into how advancing technology has changed and will change the work force, and what policies would create opportunity for more Americans in the digital economy.
That issue, he wrote, is the “defining challenge of our time.”
Three years later, the task force assembled to address it is publishing its wide-ranging conclusions. The 92-page report, “The Work of the Future: Building Better Jobs in an Age of Intelligent Machines,” was released on Tuesday….
Here are four of the key findings in the report:
Most American workers have fared poorly.
It’s well known that those on the top rungs of the job ladder have prospered for decades while wages for average American workers have stagnated. But the M.I.T. analysis goes further. It found, for example, that real wages for men without four-year college degrees have declined 10 to 20 percent since their peak in 1980….
Robots and A.I. are not about to deliver a jobless future.
…The M.I.T. researchers concluded that the change would be more evolutionary than revolutionary. In fact, they wrote, “we anticipate that in the next two decades, industrialized countries will have more job openings than workers to fill them.”…
Worker training in America needs to match the market.
“The key ingredient for success is public-private partnerships,” said Annette Parker, president of South Central College, a community college in Minnesota, and a member of the advisory board to the M.I.T. project.
The schools, nonprofits and corporate-sponsored programs that have succeeded in lifting people into middle-class jobs all echo her point: the need to link skills training to business demand….
Workers need more power, voice and representation.The report calls for raising the minimum wage, broadening unemployment insurance and modifying labor laws to enable collective bargaining in occupations like domestic and home-care workers and freelance workers. Such representation, the report notes, could come from traditional unions or worker advocacy groups like the National Domestic Workers Alliance, Jobs With Justice and the Freelancers Union….(More)”
Revised and Updated Book by Kevin Werbach and Dan Hunter on “The Power of Gamification and Game Thinking in Business, Education, Government, and Social Impact”: “For thousands of years, we’ve created things called games that tap the tremendous psychic power of fun. In a revised and updated edition of For the Win: The Power of Gamification and Game Thinking in Business, Education, Government, and Social Impact, authors Kevin Werbach and Dan Hunter argue that applying the lessons of gamification could change your business, the way you learn or teach, and even your life.
Werbach and Hunter explain how games can be used as a valuable tool to address serious pursuits like marketing, productivity enhancement, education, innovation, customer engagement, human resources, and sustainability. They reveal how, why, and when gamification works—and what not to do.
Discover the successes—and failures—of organizations that are using gamification:
How a South Korean company called Neofect is using gamification to help people recover from strokes;
How a tool called SuperBetter has demonstrated significant results treating depression, concussion symptoms, and the mental health harms of the COVID-19 pandemic through game thinking;
How the ride-hailing giant Uber once used gamification to influence their drivers to work longer hours than they otherwise wanted to, causing swift backlash.
The story of gamification isn’t fun and games by any means. It’s serious. When used carefully and thoughtfully, gamification produces great outcomes for users, in ways that are hard to replicate through other methods. Other times, companies misuse the “guided missile” of gamification to have people work and do things in ways that are against their self-interest.
This revised and updated edition incorporates the most prominent research findings to provide a comprehensive gamification playbook for the real world….(More)”.
This can be fixed, but it requires addressing two key challenges. The first is that it is often difficult for doctors to know how long patients have left to live. Even among patients in hospice care, doctors get it wrong nearly 70% of the time. Hospitals and private companies have invested millions of dollars to try and identify these outcomes, often using artificial intelligence and machine learning, although most of these algorithms have not been vetted in real-world settings.
In a recent set of studies, our team used data from real-time electronic medical records to develop a machine learning algorithm that identified which cancer patients had a high risk of dying in the next six months. We then tested the algorithm on 25,000 patients who were seen at our health system’s cancer practices and found it performed better than relying only on doctors to identify high-risk patients.
But just because such a tool exists doesn’t mean doctors will use it to prompt more conversations. The second challenge — which is even harder to overcome — is using machine learning to motivate clinicians to have difficult conversations with patients about the end of life.
We wondered if implementing a timely “nudge” that doctors received before seeing their high-risk patients could help them start the conversation.
To test this idea, we used our prediction tool in a clinical trial involving nine cancer practices. Doctors in the nudge group received a weekly report on how many end-of-life conversations they had compared to their peers, along with a list of patients they were scheduled to see the following week who the algorithm deemed at high-risk of dying in the next six months. They could review the list and uncheck any patients they thought were not appropriate for end-of-life conversations. For the patients who remained checked, doctors received a text message on the day of the appointment reminding them to discuss the patient’s goals at the end of life. Doctors in the control group did not receive the email or text message intervention.
As we reported in JAMA Oncology, 15% of doctors who received the nudge text had end-of-life conversations with their patients, compared to just 4% of the control doctors….(More)”.
Remaking the Commons: How Digital Tools Facilitate and Subvert the Common Good
Nov 18, 2020 08:47 pm
Paper by Jessica Feldman:”This scoping paper considers how digital tools, such as ICTs and AI, have failed to contribute to the “common good” in any sustained or scalable way. This is attributed to a problem that is at once political-economic and technical.
Many digital tools’ business models are predicated on advertising: framing the user as an individual consumer-to-be-targeted, not as an organization, movement, or any sort of commons. At the level of infrastructure and hardware, the increased privatization and centralization of transmission and production leads to a dangerous bottlenecking of communication power, and to labor and production practices that are undemocratic and damaging to common resources.
These practices escalate collective action problems, pose a threat to democratic decision making, aggravate issues of economic and labor inequality, and harm the environment and health. At the same time, the growth of both AI and online community formation raise questions around the very definition of human subjectivity and modes of relationality. Based on an operational definition of the common good grounded in ethics of care, sustainability, and redistributive justice, suggestions are made for solutions and further research in the areas of participatory design, digital democracy, digital labor, and environmental sustainability….(More)”
Article by Clive Thompson: “…When the open source concept emerged in the ’90s, it was conceived as a bold new form of communal labor: digital barn raisings. If you made your code open source, dozens or even hundreds of programmers would chip in to improve it. Many hands would make light work. Everyone would feel ownership.
Now, it’s true that open source has, overall, been a wild success. Every startup, when creating its own software services or products, relies on open source software from folks like Thornton: open source web-server code, open source neural-net code. But, with the exception of some big projects—like Linux—the labor involved isn’t particularly communal. Most are like Bootstrap, where the majority of the work landed on a tiny team of people.
Recently, Nadia Eghbal—the head of writer experience at the email newsletter platform Substack—published Working in Public, a fascinating book for which she spoke to hundreds of open source coders. She pinpointed the change I’m describing here. No matter how hard the programmers worked, most “still felt underwater in some shape or form,” Eghbal told me.
Why didn’t the barn-raising model pan out? As Eghbal notes, it’s partly that the random folks who pitch in make only very small contributions, like fixing a bug. Making and remaking code requires a lot of high-level synthesis—which, as it turns out, is hard to break into little pieces. It lives best in the heads of a small number of people.
Yet those poor top-level coders still need to respond to the smaller contributions (to say nothing of requests for help or reams of abuse). Their burdens, Eghbal realized, felt like those of YouTubers or Instagram influencers who feel overwhelmed by their ardent fan bases—but without the huge, ad-based remuneration.
Sometimes open source coders simply walk away: Let someone else deal with this crap. Studies suggest that about 9.5 percent of all open source code is abandoned, and a quarter is probably close to being so. This can be dangerous: If code isn’t regularly updated, it risks causing havoc if someone later relies on it. Worse, abandoned code can be hijacked for ill use. Two years ago, the pseudonymous coder right9ctrl took over a piece of open source code that was used by bitcoin firms—and then rewrote it to try to steal cryptocurrency….(More)”.
Article by Justine Calma: “Google unveiled a tool today that could help cities keep their residents cool by mapping out where trees are needed most. Cities tend to be warmer than surrounding areas because buildings and asphalt trap heat. An easy way to cool metropolitan areas down is to plant more trees in neighborhoods where they’re sparse.
Google’s new Tree Canopy Lab uses aerial imagery and Google’s AI to figure out where every tree is in a city. Tree Canopy Lab puts that information on an interactive map along with additional data on which neighborhoods are more densely populated and are more vulnerable to high temperatures. The hope is that planting new trees in these areas could help cities adapt to a warming world and save lives during heat waves.
Google piloted Tree Canopy Lab in Los Angeles. Data on hundreds more cities is on the way, the company says. City planners interested in using the tool in the future can reach out to Google through a form it posted along with today’s announcement.
“We’ll be able to really home in on where the best strategic investment will be in terms of addressing that urban heat,” says Rachel Malarich, Los Angeles’ first city forest officer.
Google claims that its new tool can save cities like Los Angeles time when it comes to taking inventory of their trees. That’s often done by sending people to survey each block. Los Angeles has also used LIDAR technology to map their urban forest in the past, which uses a laser sensor to detect the trees — but that process was expensive and slow, according to Malarich. Google’s new service, on the other hand, is free to use and will be updated regularly using images the company already takes by plane for Google Maps….(More)”.
Leveraging Open Data with a National Open Computing Strategy
Nov 18, 2020 01:47 pm
Policy Brief by Lara Mangravite and John Wilbanks: “Open data mandates and investments in public data resources, such as the Human Genome Project or the U.S. National Oceanic and Atmospheric Administration Data Discovery Portal, have provided essential data sets at a scale not possible without government support. By responsibly sharing data for wide reuse, federal policy can spur innovation inside the academy and in citizen science communities. These approaches are enabled by private-sector advances in cloud computing services and the government has benefited from innovation in this domain. However, the use of commercial products to manage the storage of and access to public data resources poses several challenges.
First, too many cloud computing systems fail to properly secure data against breaches, improperly share copies of data with other vendors, or use data to add to their own secretive and proprietary models. As a result, the public does not trust technology companies to responsibly manage public data—particularly private data of individual citizens. These fears are exacerbated by the market power of the major cloud computing providers, which may limit the ability of individuals or institutions to negotiate appropriate terms. This impacts the willingness of U.S. citizens to have their personal information included within these databases.
Second, open data solutions are springing up across multiple sectors without coordination. The federal government is funding a series of independent programs that are working to solve the same problem, leading to a costly duplication of effort across programs.
Third and most importantly, the high costs of data storage, transfer, and analysis preclude many academics, scientists, and researchers from taking advantage of governmental open data resources. Cloud computing has radically lowered the costs of high-performance computing, but it is still not free. The cost of building the wrong model at the wrong time can quickly run into tens of thousands of dollars.
Scarce resources mean that many academic data scientists are unable or unwilling to spend their limited funds to reuse data in exploratory analyses outside their narrow projects. And citizen scientists must use personal funds, which are especially scarce in communities traditionally underrepresented in research. The vast majority of public data made available through existing open science policy is therefore left unused, either as reference material or as “foreground” for new hypotheses and discoveries….The Solution: Public Cloud Computing…(More)”.
Evaluating Identity Disclosure Risk in Fully Synthetic Health Data: Model Development and Validation
Nov 18, 2020 12:45 pm
Paper by Khaled El Emam et al: “There has been growing interest in data synthesis for enabling the sharing of data for secondary analysis; however, there is a need for a comprehensive privacy risk model for fully synthetic data: If the generative models have been overfit, then it is possible to identify individuals from synthetic data and learn something new about them.
Objective: The purpose of this study is to develop and apply a methodology for evaluating the identity disclosure risks of fully synthetic data.
Methods: A full risk model is presented, which evaluates both identity disclosure and the ability of an adversary to learn something new if there is a match between a synthetic record and a real person. We term this “meaningful identity disclosure risk.” The model is applied on samples from the Washington State Hospital discharge database (2007) and the Canadian COVID-19 cases database. Both of these datasets were synthesized using a sequential decision tree process commonly used to synthesize health and social science data.
Results: The meaningful identity disclosure risk for both of these synthesized samples was below the commonly used 0.09 risk threshold (0.0198 and 0.0086, respectively), and 4 times and 5 times lower than the risk values for the original datasets, respectively.
Conclusions: We have presented a comprehensive identity disclosure risk model for fully synthetic data. The results for this synthesis method on 2 datasets demonstrate that synthesis can reduce meaningful identity disclosure risks considerably. The risk model can be applied in the future to evaluate the privacy of fully synthetic data….(More)”.
Federal Regulators Increase Focus on Patient Risks From Electronic Health Records
Nov 18, 2020 10:47 am
Ben Moscovitch at Pew: “…The Office of the National Coordinator for Health Information Technology (ONC) will collect clinicians’ feedback through a survey developed by the Urban Institute under a contract with the agency. ONC will release aggregated results as part its EHR reporting program. Congress required the program’s creation in the 21st Century Cures Act, the wide-ranging federal health legislation enacted in 2016. The act directs ONC to determine which data to gather from health information technology vendors. That information can then be used to illuminate the strengths and weaknesses of EHR products, as well as industry trends.
The Pew Charitable Trusts, major medical organizations and hospital groups, and health information technology experts have urged that the reporting program examine usability-related patient risks. Confusing, cumbersome, and poorly customized EHR systems can cause health care providers to order the wrong drug or miss test results and other information critical to safe, effective treatment. Usability challenges also can increase providers’ frustration and, in turn, their likelihood of making mistakes.
The data collected from clinicians will shed light on these problems, encourage developers to improve the safety of their products, and help hospitals and doctor’s offices make better-informed decisions about the purchase, implementation, and use of these tools. Research shows that aggregated data about EHRs can generate product-specific insights about safety deficiencies, even when health care facilities implement the same system in distinct ways….(More)”.
How the U.S. Military Buys Location Data from Ordinary Apps
Nov 18, 2020 09:08 am
Joseph Cox at Vice: “The U.S. military is buying the granular movement data of people around the world, harvested from innocuous-seeming apps, Motherboard has learned. The most popular app among a group Motherboard analyzed connected to this sort of data sale is a Muslim prayer and Quran app that has more than 98 million downloads worldwide. Others include a Muslim dating app, a popular Craigslist app, an app for following storms, and a “level” app that can be used to help, for example, install shelves in a bedroom.
Through public records, interviews with developers, and technical analysis, Motherboard uncovered two separate, parallel data streams that the U.S. military uses, or has used, to obtain location data. One relies on a company called Babel Street, which creates a product called Locate X. U.S. Special Operations Command (USSOCOM), a branch of the military tasked with counterterrorism, counterinsurgency, and special reconnaissance, bought access to Locate X to assist on overseas special forces operations. The other stream is through a company called X-Mode, which obtains location data directly from apps, then sells that data to contractors, and by extension, the military.
The news highlights the opaque location data industry and the fact that the U.S. military, which has infamously used other location data to target drone strikes, is purchasing access to sensitive data. Many of the users of apps involved in the data supply chain are Muslim, which is notable considering that the United States has waged a decades-long war on predominantly Muslim terror groups in the Middle East, and has killed hundreds of thousands of civilians during its military operations in Pakistan, Afghanistan, and Iraq. Motherboard does not know of any specific operations in which this type of app-based location data has been used by the U.S. military.
The apps sending data to X-Mode include Muslim Pro, an app that reminds users when to pray and what direction Mecca is in relation to the user’s current location. The app has been downloaded over 50 million times on Android, according to the Google Play Store, and over 98 million in total across other platforms including iOS, according to Muslim Pro’s website….(More)”.
Blog post by Bill Gates: “My family loves to do jigsaw puzzles. It’s one of our favorite activities to do together, especially when we’re on vacation. There is something so satisfying about everyone working as a team to put down piece after piece until finally the whole thing is done.
In a lot of ways, the fight against Alzheimer’s disease reminds me of doing a puzzle. Your goal is to see the whole picture, so that you can understand the disease well enough to better diagnose and treat it. But in order to see the complete picture, you need to figure out how all of the pieces fit together.
Right now, all over the world, researchers are collecting data about Alzheimer’s disease. Some of these scientists are working on drug trials aimed at finding a way to stop the disease’s progression. Others are studying how our brain works, or how it changes as we age. In each case, they’re learning new things about the disease.
But until recently, Alzheimer’s researchers often had to jump through a lot of hoops to share their data—to see if and how the puzzle pieces fit together. There are a few reasons for this. For one thing, there is a lot of confusion about what information you can and can’t share because of patient privacy. Often there weren’t easily available tools and technologies to facilitate broad data-sharing and access. In addition, pharmaceutical companies invest a lot of money into clinical trials, and often they aren’t eager for their competitors to benefit from that investment, especially when the programs are still ongoing.
Unfortunately, this siloed approach to research data hasn’t yielded great results. We have only made incremental progress in therapeutics since the late 1990s. There’s a lot that we still don’t know about Alzheimer’s, including what part of the brain breaks down first and how or when you should intervene. But I’m hopeful that will change soon thanks in part to the Alzheimer’s Disease Data Initiative, or ADDI….(More)“.
CrowdHeritage: Improving the quality of Cultural Heritage through crowdsourcing methods
Nov 16, 2020 06:18 am
Paper by Maria Ralli et al: “The lack of granular and rich descriptive metadata highly affects the discoverability and usability of the digital content stored in museums, libraries and archives, aggregated and served through Europeana, thus often frustrating the user experience offered by these institutions’ portals. In this context, metadata enrichment services through automated analysis and feature extraction along with crowdsourcing annotation services can offer a great opportunity for improving the metadata quality of digital cultural content in a scalable way, while at the same time engaging different user communities and raising awareness about cultural heritage assets. Such an effort is Crowdheritage, an open crowdsourcing platform that aims to employ machine and human intelligence in order to improve the digital cultural content metadata quality….(More)”.
Algorithmic governance: A modes of governance approach
Nov 16, 2020 06:08 am
Article by Daria Gritsenko and Matthew Wood: “This article examines how modes of governance are reconfigured as a result of using algorithms in the governance process. We argue that deploying algorithmic systems creates a shift toward a special form of design‐based governance, with power exercised ex ante via choice architectures defined through protocols, requiring lower levels of commitment from governing actors. We use governance of three policy problems – speeding, disinformation, and social sharing – to illustrate what happens when algorithms are deployed to enable coordination in modes of hierarchical governance, self‐governance, and co‐governance. Our analysis shows that algorithms increase efficiency while decreasing the space for governing actors’ discretion. Furthermore, we compare the effects of algorithms in each of these cases and explore sources of convergence and divergence between the governance modes. We suggest design‐based governance modes that rely on algorithmic systems might be re‐conceptualized as algorithmic governance to account for the prevalence of algorithms and the significance of their effects….(More)”.
The political choreography of the Sophia robot: beyond robot rights and citizenship to political performances for the social robotics market
Nov 15, 2020 05:11 pm
Paper by A humanoid robot named ‘Sophia’ has sparked controversy since it has been given citizenship and has done media performances all over the world. The company that made the robot, Hanson Robotics, has touted Sophia as the future of artificial intelligence (AI). Robot scientists and philosophers have been more pessimistic about its capabilities, describing Sophia as a sophisticated puppet or chatbot. Looking behind the rhetoric about Sophia’s citizenship and intelligence and going beyond recent discussions on the moral status or legal personhood of AI robots, we analyse the performativity of Sophia from the perspective of what we call ‘political choreography’: drawing on phenomenological approaches to performance-oriented philosophy of technology. This paper proposes to interpret and discuss the world tour of Sophia as a political choreography that boosts the rise of the social robot market, rather than a statement about robot citizenship or artificial intelligence. We argue that the media performances of the Sophia robot were choreographed to advance specific political interests. We illustrate our philosophical discussion with media material of the Sophia performance, which helps us to explore the mechanisms through which the media spectacle functions hand in hand with advancing the economic interests of technology industries and their governmental promotors. Using a phenomenological approach and attending to the movement of robots, we also criticize the notion of ‘embodied intelligence’ used in the context of social robotics and AI. In this way, we put the discussions about the robot’s rights or citizenship in the context of AI politics and economics….(More)”
Extending the framework of algorithmic regulation. The Uber case
Nov 14, 2020 04:59 pm
Paper by Florian Eyert, Florian Irgmaier, and Lena Ulbricht: “In this article, we take forward recent initiatives to assess regulation based on contemporary computer technologies such as big data and artificial intelligence. In order to characterize current phenomena of regulation in the digital age, we build on Karen Yeung’s concept of “algorithmic regulation,” extending it by building bridges to the fields of quantification, classification, and evaluation research, as well as to science and technology studies. This allows us to develop a more fine‐grained conceptual framework that analyzes the three components of algorithmic regulation as representation, direction, and intervention and proposes subdimensions for each. Based on a case study of the algorithmic regulation of Uber drivers, we show the usefulness of the framework for assessing regulation in the digital age and as a starting point for critique and alternative models of algorithmic regulation….(More)”.
Building Trust for Inter-Organizational Data Sharing: The Case of the MLDE
Nov 14, 2020 05:46 am
Paper by Heather McKay, Sara Haviland, and Suzanne Michael: “There is increasing interest in sharing data across agencies and even between states that was once siloed in separate agencies. Driving this is a need to better understand how people experience education and work, and their pathways through each. A data-sharing approach offers many possible advantages, allowing states to leverage pre-existing data systems to conduct increasingly sophisticated and complete analyses. However, information sharing across state organizations presents a series of complex challenges, one of which is the central role trust plays in building successful data-sharing systems. Trust building between organizations is therefore crucial to ensuring project success.
This brief examines the process of building trust within the context of the development and implementation of the Multistate Longitudinal Data Exchange (MLDE). The brief is based on research and evaluation activities conducted by Rutgers’ Education & Employment Research Center (EERC) over the past five years, which included 40 interviews with state leaders and the Western Interstate Commission for Higher Education (WICHE) staff, observations of user group meetings, surveys, and MLDE document analysis. It is one in a series of MLDE briefs developed by EERC….(More)”.
Paper by Cass R. Sunstein: “Behavioral science is playing an increasing role in public policy, and it is raising new questions about fundamental issues – the role of government, freedom of choice, paternalism, and human welfare. In diverse nations, public officials are using behavioral findings to combat serious problems – poverty, air pollution, highway safety, COVID-19, discrimination, employment, climate change, and occupational health. Exploring theory and practice, this Element attempts to provide one-stop shopping for those who are new to the area and for those who are familiar with it. With reference to nudges, taxes, mandates, and bans, it offers concrete examples of behaviorally informed policies. It also engages the fundamental questions, include the proper analysis of human welfare in light of behavioral findings. It offers a plea for respecting freedom of choice – so long as people’s choices are adequately informed and free from behavioral biases….(More)”.
European Commission Press Release: “The set-up of the European Health Data Space will be an integral part of building a European Health Union, a process launched by the Commission today with a first set of proposals to reinforce preparedness and response during health crisis. This is also a direct follow up of the Data strategy adopted by the Commission in February this year, where the Commission had already stressed the importance of creating European data spaces, including on health….
In this perspective, as part of the implementation of the Data strategy, a data governance act is set to be presented still this year, which will support the reuse of public sensitive data such as health data. A dedicated legislative proposal on a European health data space is planned for next year, as set out in the 2021 Commission work programme.
As first steps, the following activities starting in 2021 will pave the way for better data-driven health care in Europe:
The Commission proposes a European Health Data Space in 2021;
A Joint Action with 22 Member States to propose options on governance, infrastructure, data quality and data solidarity and empowering citizens with regards to secondary health data use in the EU;
Investments to support the European Health Data Space under the EU4Health programme, as well as common data spaces and digital health related innovation under Horizon Europe and the Digital Europe programmes;
Engagement with relevant actors to develop targeted Codes of Conduct for secondary health data use;
A pilot project, to demonstrate the feasibility of cross border analysis for healthcare improvement, regulation and innovation;
Other EU funding opportunities for digital transformation of health and care will be available for Member States as of 2021 under Recovery and Resilience Facility, European Regional Development Fund, European Social Fund+, InvestEU.
The set of proposals adopted by the Commission today to strengthen the EU’s crisis preparedness and response, taking the first steps towards a European Health Union, also pave the way for the participation of the European Medicines Agency (EMA) and the European Centre for Disease Prevention and Control (ECDC) in the future European Health Data Space infrastructure, along with research institutes, public health bodies, and data permit authorities in the Member States….(More)”.